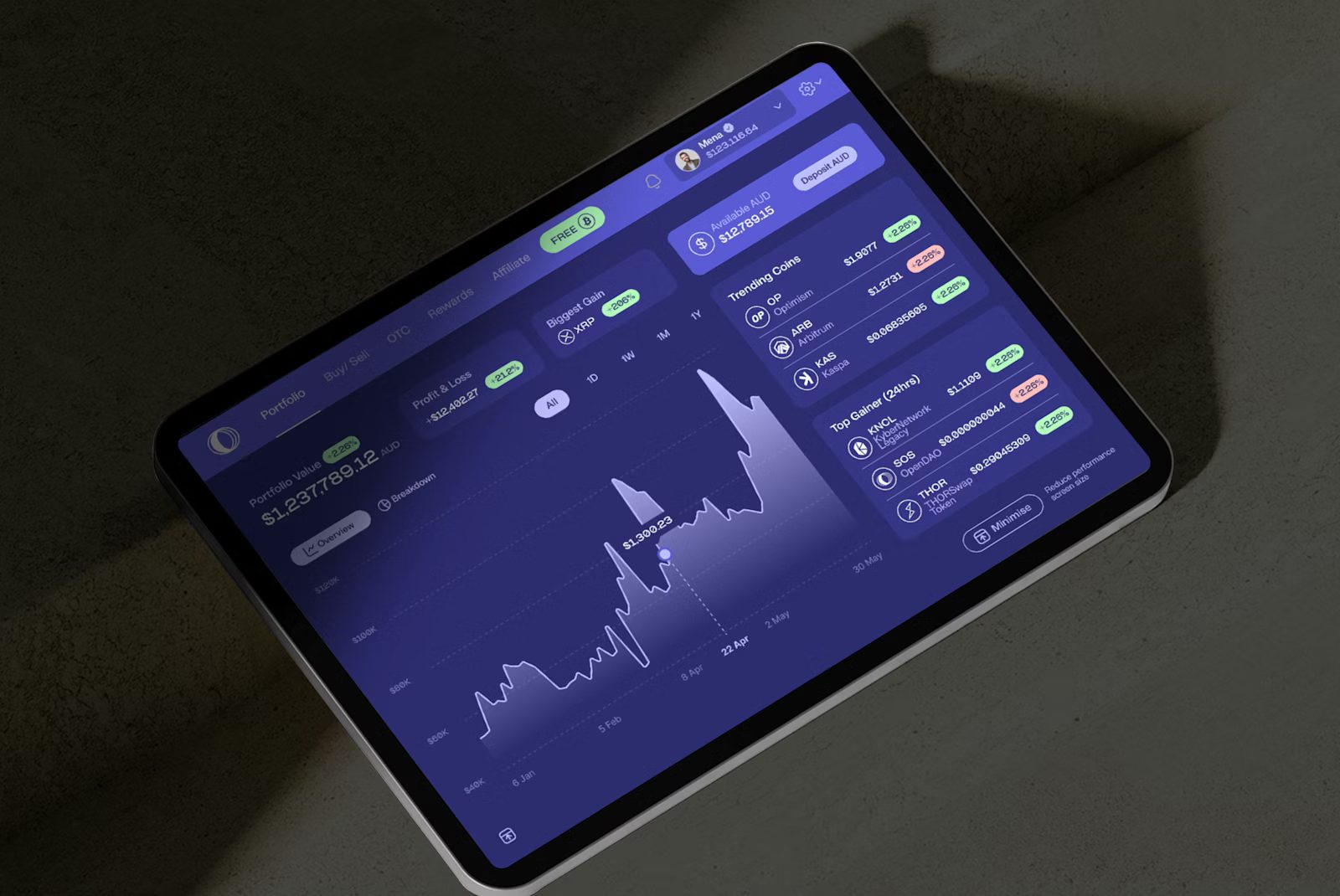
This is a due-diligence guide, not a momentum list. The point is to give Radar readers a repeatable way to compare protocols before surface growth starts doing too much of the talking.
Prediction-market protocols are easy to overread because attention and product quality are not the same thing. On Arbitrum, the cleaner comparison starts with trust: can the market resolve correctly, stay liquid enough to matter, and keep users coming back after one incentives cycle ends?
Explore Hub: Prediction Market
Core Comparison Criteria
- Resolution trust: If users cannot explain who settles outcomes and how disputes are handled, the protocol deserves a lower quality score immediately.
- Liquidity durability: A prediction market without dependable depth may still look active, but it is not necessarily useful once real sizing enters the room.
- Market variety: Repeated engagement across different event types is stronger than one isolated hot lane.
- User return logic: A protocol that gives users a reason to come back beyond one narrative spike is more interesting than a protocol riding one temporary theme.
Red Flags
- Incentives doing more work than genuine user demand.
- Resolution or dispute processes that remain too opaque for non-insiders.
- One market or one event type explaining nearly all visible activity.
- Liquidity that looks fine until you imagine a real exit window.
Decision Loop
- Start with resolution and trust before you look at growth numbers.
- Check whether depth holds up in the markets that matter most.
- Compare protocol activity across event types, not just one highlighted market.
- Only then decide which names deserve deeper research time.
A good comparison framework slows you down in the right places. If the protocol still looks attractive after these checks, then the interest is more likely to be durable instead of purely cosmetic.
Continue this cluster
Stay inside the same cluster so the logic compounds instead of resetting on the next click.